El Análisis Factorial Confirmatorio (AFC; Confirmatory Factor Analysis en inglés) es un conjunto de técnicas que se emplean para la validación de cuestionarios. Es decir, permite conocer la operacionalización de un modelo de medida (Kelloway, 2015). Esta estrategia de análisis será adecuada cuando haya un debate entorno a la dimensionalidad de la estructura factorial de la escala de medida objeto de estudio.
Caso práctico
En un equipo de baloncesto se quiere medir la personalidad de sus jugadores. Para ello, se ha usado un cuestionario tipo Likert que contiene 18 ítems distribuidos en cinco rasgos generales de personalidad, propuestos por el Modelo Ocean (también conocido como Five-factor model of personality): neuroticismo, extraversión, afabilidad, escrupulosidad y apertura a la experiencia.
Pero antes de poder tomar estos datos del equipo de baloncesto, se ha recogido esta información en 200 jugadores de baloncesto de distintos clubes nacionales con el objetivo de conocer la dimensionalidad de la escala y poder validarla adecuadamente para este grupo poblacional.
Por tanto, para este ejemplo, se usarán las siguiente base de datos con la respuesta ficticia de 200 jóvenes. El cuestionario se compone de 18 ítems, que son cada una de las columnas que formarán parte de esta base de datos. Puedes descargar la base de datos haciendo clic en el siguiente botón:
Como viene siendo habitual, para este ejemplo se usará la versión Mplus7 en un ordenador Windows 10 empleando la base de datos que se puede descargar pulsando el siguiente botón y que tiene como título Personalidad.dat.
Procedimiento
En primer lugar, para un análisis confirmatorio necesitaremos solicitar distintas ecuaciones estructurales. Aquí tampoco nos deberemos preocupar en exceso por las formas de dichas ecuaciones. Más bien, deberemos definir las variables latentes (o variables no observadas) que corresponderán con los factores que deseamos obtener (cinco en este caso; correspondientes con los tipos de personalidad). Para ello, especificaremos en el apartado de Model los factores y los ítems que están relacionados con ellos (los que mayor carga factorial hayan obtenido en un posible Análisis Factorial Exploratorio).
La sintaxis que solicitaremos para un análisis confirmatorio básico será:
Title:
Análisis Factorial Confirmatorio - Personalidad
Data:
File is "C:/Root/Mplus/Personalidad.dat";
Variable:
Names are Item1-Item18;
Model:
Neuras BY Item10 Item12 Item16 Item18;
Extra BY Item2 Item4 Item9 Item14;
Afabi BY Item3 Item6 Item11 Item17;
Escru BY Item1 Item5 Item7;
Apert BY Item8 Item13 Item15;
Output:
Standardized modindices (all);
- En Title: pondremos un título a nuestro análisis (esto solo es para que el usuario sepa el nombre del análisis).
- A continuación, en Data:, especificaremos el lugar en el que se encuentra la base de datos en formato .dat. Para ello, tendremos que usar el directorio de Windows (cambiando las barras de "\" a "/"). La dirección que ves arriba será distinta en tu caso.
- Después, en Variable: nombraremos todas las variables (names are). Puesto que en este caso las variables se llaman similar salvo el número del ítem podemos usar la función elemento inicial-elemento final (Item1-Item4) para indicarle cómo las debe nombrar automáticamente siguiendo el orden de aparición en la base de datos.
- En el apartado de Model: especificaremos los factores que deberemos confirmar junto con los ítems que pertencen a dicho factor a través de la fórmula Factor BY Relación de ítems.
- Finalmente, en el apartado de Output: especificaremos la forma que mostrará todos los resultados.
Cuando ponemos esta sintaxis en Mplus y le damos al botón RUN, el programa hace distintos cálculos y procesos por defecto. En primer lugar, el software permite que las variables latentes (factores) se puedan correlacionar. En el caso contrario (en el caso que queramos realizar un análisis factorial ortogonal) debemos declarar que estas correlaciones sean cero en con la siguiente sintaxis en el apartado de
Model:
Model:
Neuras BY Item10 Item12 Item15 Item20;
Extra BY Item2 Item4 Item9 Item14;
Afabi BY Item3 Item6 Item11 Item17;
Escru BY Item1 Item5 Item7;
Apert BY Item8 Item13 Item15;
Neuras WITH Extra @ 0;
Neuras WITH Afabi @ 0;
Neuras WITH Escru @ 0;
Neuras WITH Apert @ 0;
Y así sucesivamente hasta que estén cubiertas todas las correlaciones.
En segundo lugar, las variables latentes se definen por defecto como variables no observadas y por lo tanto no tienen escala de medida. Por tanto, Mplus configura el primer parámetro de cada variable latente igual a 1. Por tanto, la variable latente se mide en la misma escala que las variables observadas (los ítems). Estos parámetros no se estiman, más bien se simplifican a 1. Entonces, si se quiere que las variables latentes sean estimadas por cualquier otra variable indicadora, deberemos indicar en el apartado de Model: que se libere el parámetro por defecto (uso del asterisco) y que se asigne un nuevo parámetro. Veamos esto último con un ejemplo:
Model:
Neuras BY Item10 Item12 Item15 Item20;
Extra BY Item2 Item4 Item9 Item14;
Afabi BY Item3 Item6 Item11 Item17;
Escru BY Item1 Item5 Item7;
Apert BY Item8 Item13 Item15;
Escru BY Item1 *;
Escru BY Item4 @ 1;
Estas dos cosas que acabamos de ver, no las vamos a aplicar de momento en nuestro análisis, pero sí que merecía la pena introducirlas para futuras modificaciones del análisis.
Resultados
Vamos a subdividir el apartado de resultados en varias secciones. Comencemos por la Estimación. La primera parte de los resultados, nos muestra el número de participantes que rellenaron el cuestionario, el número de variables dependientes y sus nombres (que corresponde con el número del ítem del ficticio cuestionario), el número de variables latentes y sus nombres (que corresponde con el nombre de las variables). Además, también se muestra el tipo de estimador usado (máxima verosimilitud por defecto). Nótese que como las variables observables son causadas por las variables latentes, estas son propuestas como variables dependientes.
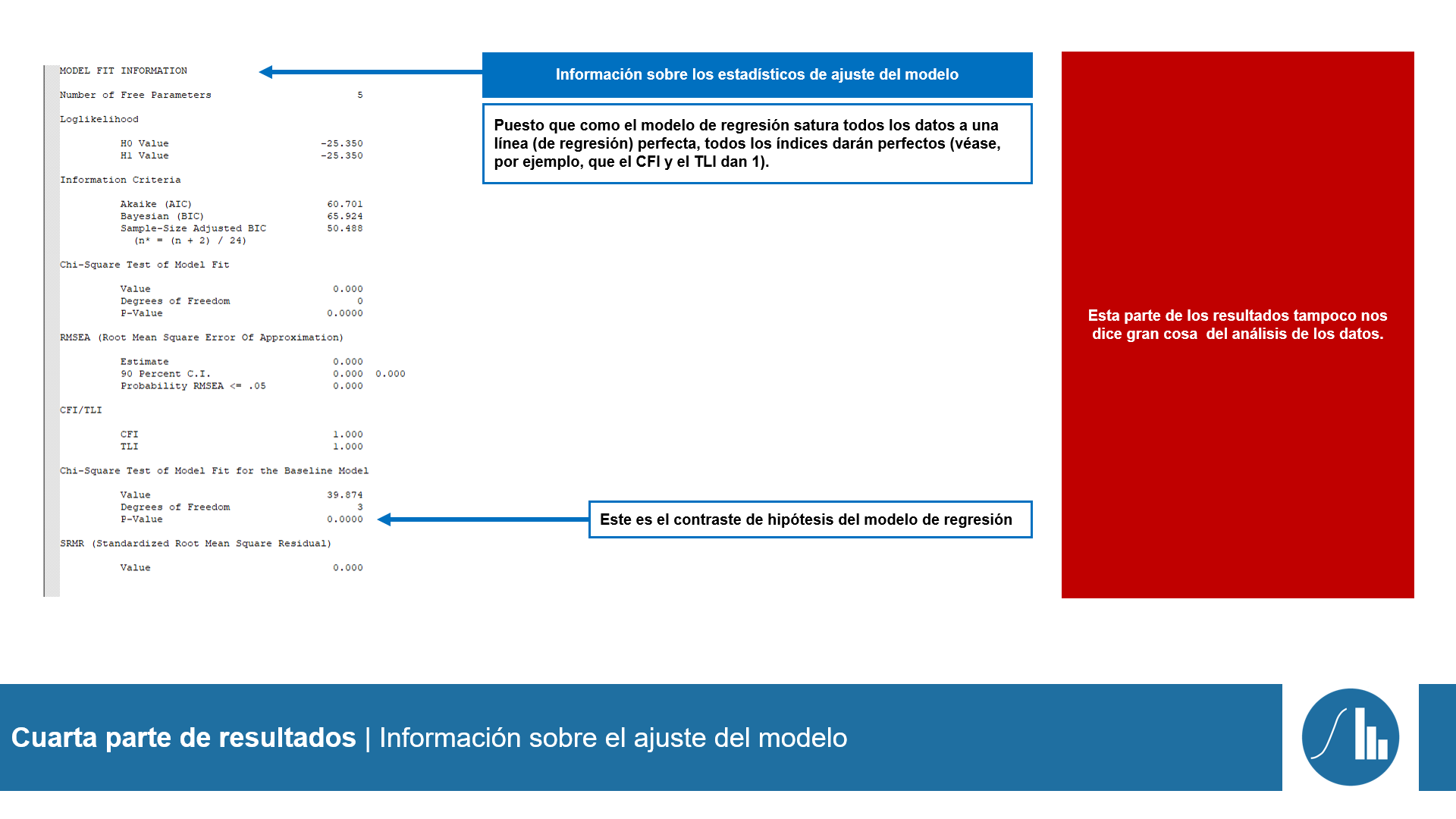
A continuación, obtenemos la
evaluación del ajuste (
Assessment of fit o
Model fit information). Se trata de un conjunto de resultados que establecen la idoneidad del modelo. De manera práctica hay que ver que ciertos índices tengan un valor superior o inferior a un estándar, tal y como se muestra en la siguiente tabla de la ilustración.
Esta sección evalúa el ajuste de un modelo basado en cinco factores según si dicho modelo ofrece un ajuste absoluto de los datos y si el modelo presenta un ajuste adecuado frente a otras especificaciones. En este caso, y sin ánimo de entrar en profundidad en este análisis básico, observamos que los índices más importantes del ajuste son satisfactorios aunque no excelentes.
A continuación, nos encontramos con los resultados del modelo propiamente dichos. Aquí nos vamos a encontrar similares tablas cambiando únicamente el tipo de estandarización. La primera subsección que nos encontraremos será la de la solución no estandarizada (Unstandarized estimates):
A continuación, en la sección de resultados podemos encontrar los resultados estandarizados de tres manera distintas: STDYX (Estandariza según las varianzas de las variables observadas y latentes), STDY (Estandariza según las varianzas de las variables observadas) y STD (Estandariza según las varianzas de las variables latentes). Estos tres resultados se interpretan de manera muy similar, por lo que aquí simplemente se va a mostrar los resultados según la STDYX:
A continuación, debemos analizar la R al cuadrado, que viene después de las subsecciones de resultados estandarizadas. Estas son las comunalidades de la solución o lo que es lo mismo, el porcentaje de la varianza de cada ítem explicada por el modelo hipotetizado.
A continuación, nos encontramos el apartado de la modificación de índices, que indica la cantidad de valor del Chi-cuadrado que descenderá si un parámetro dado es liberado. Por ejemplo, si liberásemos la correlación residual entre el Ítem 18 con el Ítem 3 (ITEM18 WITH ITEM3) disminuiría el valor Chi-cuadrado hasta 19,535. A continuación, podemos observar como Mplus también reporta el cambio del parámetro esperado: por tanto, si liberásemos esta correlación residual, el parámetro no estandarizado (EPC) sería 0,378, el parámetro estandarizado STD sería también 0,378 y el parámetro estandarizado STDYX tomaría el valor de 0,359.
Informe de resultados
Puesto que lo que se está mostrando en esta entrada consiste en un análisis básico, no profundizaremos en cómo interpretar los resultados más allá de lo que ya hemos visto. Lo que sí que haremos será decir de donde se sacan todos los valores que se suelen emplear para escribir el apartado de resultados cuando se usan este tipo de análisis:
- Ajuste del modelo - MODEL FIT INFORMATION | Mirar RMSEA, CFI/TLI y SRMR (para un análisis más complejo también se mira el Chi-Square Test of Model fit)
- Comportamiento de las cargas factoriales para cada ítem y factor - Diagrama | Aconsejable observar los valores STDYX.
- Correlación interfactor - Apartado WITH de los resultados principales (aconsejable que sea la tabla correspondiente con STDYX)
Por supuesto todo esto puede ser mucho más complejo. Sin embargo, con esto hemos cubierto lo más básico del Análisis Factorial Confirmatorio.
Seguir aprendiendo
Haz clic en el siguiente botón para seguir aprendiendo sobre la realización de un modelo menos restrictivo al Análisis Factorial Confirmatorio:
Jacob Sierra Díaz y Alti