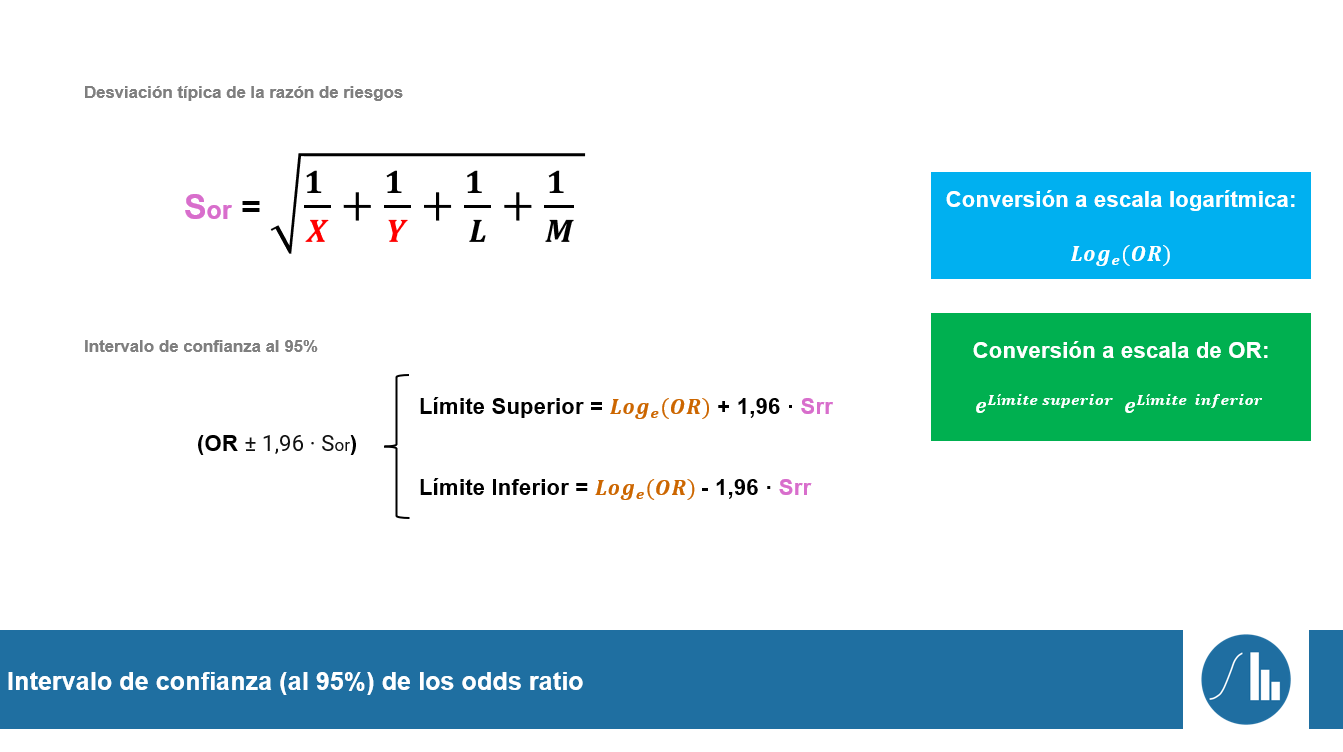
La diferencia de medias no estandarizada (mean difference en inglés; MD abreviado en dicho idioma) es, como su propio nombre indica, la diferencia entre las medias que se hayan entre dos grupos objeto de estudio o entre las medias que puede haber de un grupo entre la primera medida (pre-test) y la última medida (post-test) de una intervención. Forma parte de la familia de índices d.
Para entender bien cómo se emplea este tamaño de efecto, vamos a analizar un ejemplo práctico para luego, pasar a la fórmula final.
Caso práctico
Se ha realizado una investigación con dos grupos con el objetivo de analizar la tasa de errores lingüísticos en aprendices de la lengua castellana tras una intervención de un innovador método de enseñanza de una duración de tres semanas. El grupo experimental (n = 30) participó en dicha estrategia innovadora mientras que el grupo control (n = 31) vivenció una enseñanza tradicional. Al acabar la intervención se realizó un examen en el que se evaluó el índice de fallos.
Una vez elaborada la base de datos acerca de los resultados del examen (tasa de errores), se obtuvo la media y la desviación típica de ambos grupos: en el grupo experimental se obtuvo 9,3 ± 2,9 y en el grupo control 12,3 ± 5,7. ¿Hay diferencias estadísticamente significativas producto de la metodología empleada?
Procedimiento, resultados e interpretación
Para calcular la diferencia de medias no estandarizada (mean difference) es recomendable recoger toda la información que necesitamos en una tabla de doble entrada, teniendo en cuenta las medias y desviaciones típicas de ambos grupos.
- Como su nombre indica, debemos realizar una resta entre la media del grupo experimental y la del grupo control. En este caso, 9,3 - 12,3 = -3.
- A continuación realizaremos la desviación típica de dicha diferencia de medias aplicando la fórmula que muestra en la siguiente imagen.
- Por último, calcularemos los intervalos de confianza al 95% teniendo en cuenta la fórmula que también se muestra en la imagen y los datos que hemos calculado anteriormente.

Entonces, el grupo experimental que recibió la nueva metodología experimenta 3 veces menos de fallos lingüísticos en comparación con las enseñanzas tradicionales del grupo control. Con respecto al intervalo de confianza, no está el valor 0 incluido; por tanto, se puede generalizar a la población de estudiantes la existencia de una reducción estadísticamente significativa del número de fallos lingüísticos fruto del nuevo planteamiento pedagógico en comparación con la enseñanza tradicional.
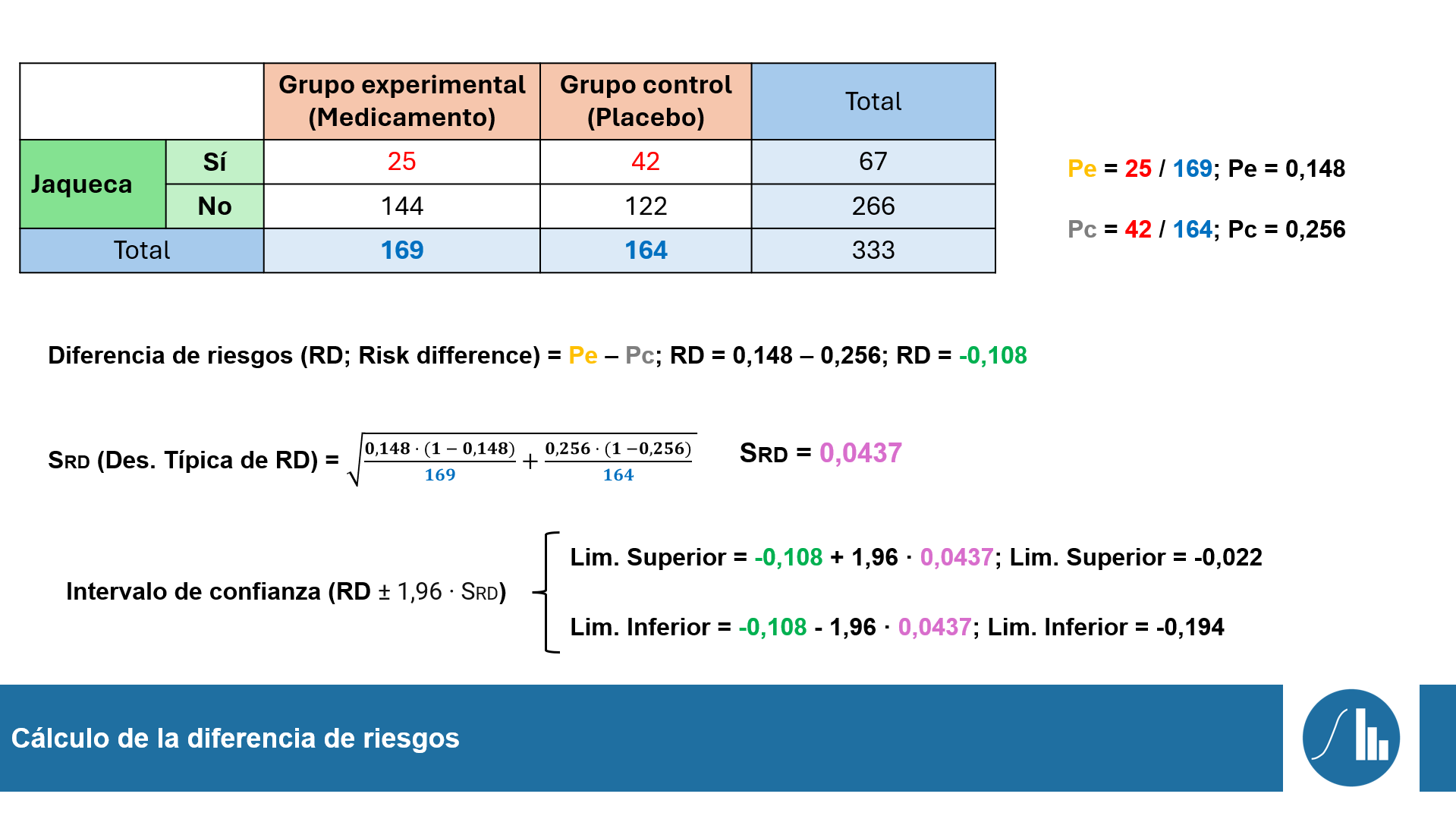
Con estos resultados, podemos concluir, en primer lugar, que un valor de diferencia de riesgos de -0,108 significa que en el grupo experimental que recibió el medicamento se ha producido un 10,8% menos de incidencia. En segundo lugar, al no encontrarse el valor 0 dentro del intervalo de confianza al 95% (-0,022; -0,194) se puede concluir que en el estudio se observan diferencia estadísticamente significativas entre la incidencia de la jaqueca entre los dos grupos. Por tanto, es posible generalizar a la población la existencia de una menor frecuencia de jaquecas cuando se aplica este nuevo medicamento, aunque más investigaciones serán necesarias al respecto.
Siguiente paso
Una vez visto un ejemplo de aplicación, vamos a ver la teoría y la fórmula de este índice. Para ello, haz clic en el siguiente botón:

Jacob Sierra Díaz y Alti